Die Hölle ist gefroren
von Christoph
Ich bin schon sehr lange im Microsoft-Umfeld unterwegs. Das fing an mit Windows 95 und Turbo Pascal, wechselte dann über Borland Delphi zu Visual C++ 6. In der Uni ging es dann per Visual Studio.NET (2002-2005) zum .NET Framework mit allem Drum und Dran: Windows Forms, Remoting, XML Webservices.
Eines war die ganze Zeit aber klar: Unter Linux kannste das komplett vergessen. Es gab da zwar schon Mono, ich tat das aber als Frickler-Kopie ab. Die haben sich irgendwie die Funktionalität angeguckt und daraus Code engineered. Das kippte in den letzten Jahren. MS hat quasi alles .NET Core als Open Source rausgehauen, hat Github gekauft und unterstützt die Runtime selbst und offiziell auf Linux.
Da ich alle meine Web-Projekte (just for the fun of it) zwischenzeitlich auf ASP.NET Core (aktuell v2.1 LTS) umgestellt habe, reizte es mich natürlich, das mal mit eigenen Augen unter Linux sehen. Was soll ich sagen? Läuft!
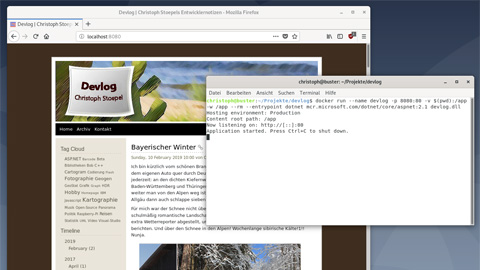
Die Dokumentation, um das mit den offiziellen Docker-Images zu erreichen, ist leider nicht die Beste. Auf mich wirkt es sehr umständlich, immer ein eigenes Image zu erzeugen um da sein Zeug reinzupacken, aber es geht natürlich dabei um Produktions-Deployments. Da will man genau ein Image irgendwo hinkopieren. Ich dagegen wollte nur mal schnell die Bits meines Windows-Deployments (vom Server kopiert) unter Linux ASP.NET testen. Dazu findet man nichts, aber das geht auch:
docker run --name devlog -p 8080:80 -v $(pwd):/app -w /app \
--rm --entrypoint dotnet mcr.microsoft.com/dotnet/core/aspnet:2.1 \
devlog.dllOder etwas eleganter und archivierbarer als docker-compose.yml:
Tags: ASP.NET Open-Source