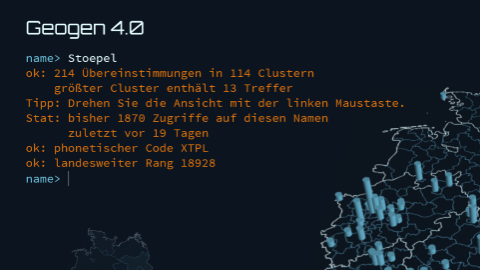
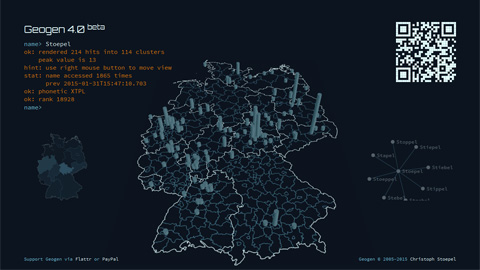
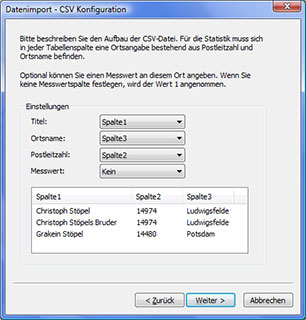
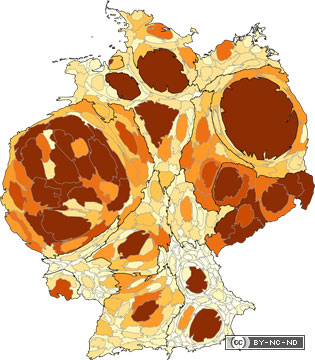
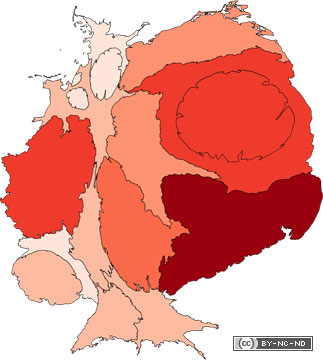
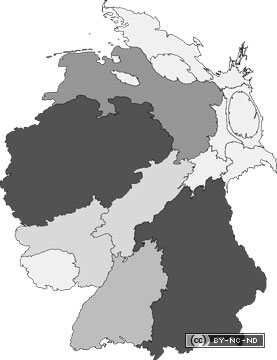
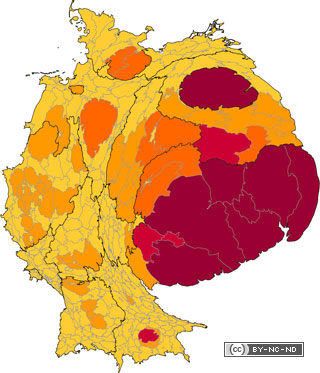
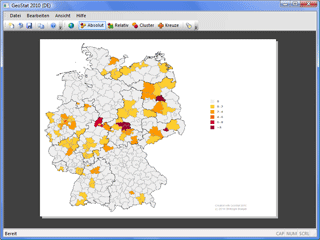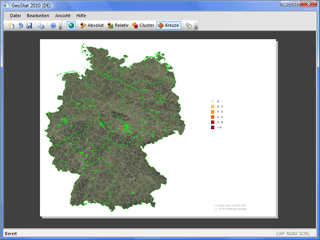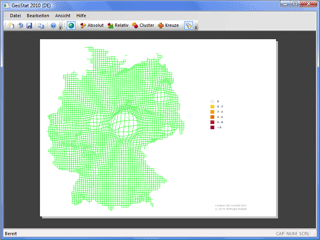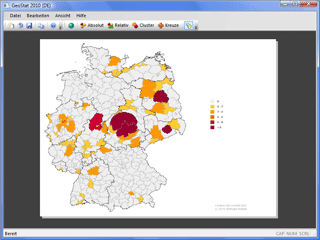
Abstract: Für das Familientreffen der Stöpels
an Pfingsten 2007 habe ich mich (als anerkannter Experte, was sonst?) um die Kartierung
unseres Namens gekümmert. Diesmal sollte es allerdings historisch sein. Da es zu
dieser Zeit noch keine einfache frei verfügbare Möglichkeit gab, musste wieder "Selbst
ist der Mann" ran. Die entstandene Software ist im
Beta-Labor meiner Homepage unter dem Namen "Geogen vNext" zu finden.
Sie verfügt über die folgenden Eigenschaften:
- Import von
Gedcoms
- Laden von Mormonen-Daten via familysearch.org
(deren seit 1,5 Jahren angekündigte Webservice-Schnittstelle steht immer noch nicht)
- Georeferenzierung mit Hilfe des "Genealogischen Ortsverzeichnisses (GOV)"
des Vereins für Computergenealogie (GenWiki
usw.)
- Export der referenzierten Daten in Gedcom oder HTML
Die Georeferenzierung ist hier wiedermal der Knackpunkt. Im Regelfall wird man sich
auf Mormonendaten beziehen. Das ist die einfachste Möglichkeit, wenn die eigene
Ahnenforschung noch nicht besonders weit fortgeschritten ist (Anmerkung: es gibt
ein sehr interessantes Projekt von den GenWiki-Leuten, um verschiedene Quellen zu
vernetzen, der Name war Genesis wenn ich mich recht erinnere). Diese liefern Personendaten
einschließlich Ortsbeschreibung in Form komma-separierter Pfadangaben vom Groben
zum Feinen. Zum Beispiel also so: "Deutschland, Brandenburg, Mittelstedt".
Das war eine freundliche Angabe. Es gibt aber auch solche wie "Sachsen Prussia,
Mittelstedt" oder noch gemeiner "Sachsen Prussia". Spätestens hier
beginnt der zeitgenössische Namenskartierer die eindeutigen Identifikatoren zu vermissen,
die Postleitzahlen.
Bei aktuellen Daten ist die Lokalisierung einfach: Postleitzahl und Ortsname genommen
und in der Datenbank nachgeschlagen (bei Geogen die
OpenGeoDb mit 30000 Ortseinträgen für Deutschland). Was aber machen wir
nun mit Mittelstedt ohne Postleitzahl? Eine Datenbankabfrage, diesmal an das
GOV, liefert 30 Treffer (hypothetisch). Es bleibt also nur, den Pfad der
Ortsspezifikation abzulaufen, um überschüssiges auszuschließen. Eine Einschränkung
auf Brandenburg ergibt allerdings gar keinen Treffer, weil sich die Grenzen in den
letzten 250 Jahren verschoben haben und das heutige Sachsen gemeint ist.
Die schlechte Nachricht: Dieses Problem ist nicht lösbar. Hier kann man nur schätzen
und raten. Das jedoch so, dass man (a) mit dem Ergebnis mit hoher Wahrscheinlichkeit
richtig liegt und (b) ein Fehlschlag möglichst wenig negative Auswirkungen hat.
Umgesetzt wird dies in "Geogen vNext" durch eine Lokalisierungspipeline,
die verschiedene Algorithmen aneinanderreiht, wobei mit dem genauesten begonnen
wird.
 Man stelle sich das wie eine Reihe von Sieben vor.
Das erste hat die kleinste Löcher und liefert die besten Ergebnisse (exakter Treffer
für Mittelstedt). Alles was hier nicht durchfällt geht in ein gröberes Sieb und
dann in das nächstgröbere. Die derzeitige Implementierung besteht aus 6 solcher
Stufen, wobei die letzte standardmäßig deaktiviert ist (Mittelwertbildung, sehr
gierig und sehr grob).
Man stelle sich das wie eine Reihe von Sieben vor.
Das erste hat die kleinste Löcher und liefert die besten Ergebnisse (exakter Treffer
für Mittelstedt). Alles was hier nicht durchfällt geht in ein gröberes Sieb und
dann in das nächstgröbere. Die derzeitige Implementierung besteht aus 6 solcher
Stufen, wobei die letzte standardmäßig deaktiviert ist (Mittelwertbildung, sehr
gierig und sehr grob).
Meiner mathematischen Meinung nach sind die Resultate nicht zufriedenstellend. Gut
ein Viertel der Mormonen-Daten ist so schlecht, dass man die Lokalisierung komplett
vergessen kann. Vom Rest beißt sich die Pipeline an etwa 15% die Zähne aus und lokalisiert
falsch! Das heißt ein Ort kann schlimmstenfalls 1000km neben seiner eigentlichen
Position liegen, weil es noch mehrere gleichnamige gibt und der falsche gewählt
wurde oder weil sich der Mikrofilmer vertippt hat. An dieser Stelle hilft leider
nur der manuelle Eingriff. Dessen sollte man sich bei Verwendung des Programmes
bewusst sein (ich habe schon einige euphorische Mails drosseln müssen).
Conclusion: Leider stößt der Informatiker und damit der Automatismus beim Problem
historischer Kartierung an Grenzen. Ein absolut genaues Verfahren ist aufgrund der
schlechten Qualität der Mormonendaten nicht möglich. Der Einsatz von Heuristiken
führt zu Ergebnissen, die nicht ruhigen Gewissens zur Veröffentlichung geeignet
sind. Es gibt aber sicherlich auch bessere Implemententierungen als die Meine. Ein
möglicher Ausweg wäre die Verlagerung der manuellen Qualitätssicherung auf eine
Community. Hierfür fehlen mir allerdings die Resourcen (und in anbetracht des Randthemas
ehrlicherweise auch etwas die Motivation).