Marktperformance 2021
von Christoph
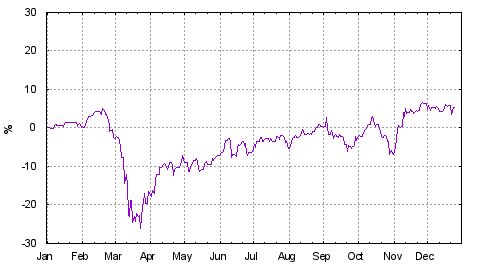
Dies ist die Fortsetzung meines Marktrückblicks von 2020. Es lief 2021 sehr gut. Beängstigend gut. So gut, dass statistisch gesehen die nächsten Jahre ziemlich mau ausfallen müssen damit der langfristige Mittelwert wieder passt. Ich habe lange überlegt, wie die Veränderung von 34% zu interpretieren ist. Wertsteigerung oder doch eher Kaufkraftverlust (Inflation)?
Da ich kein Volkswirt bin, muss ich mir hier mit einfacher Laienlogik helfen. Wertzuwachs hat für mich etwas von Leistung. Man hat eine besonders gute Strategie (Auswahl, Timing oder beides) und schlägt damit den Markt (dollargehandelter thesaurierender MSCI World dieses Jahr in € bei 32,6%). Inflation passiert einfach, egal was man macht. Bezüglich ersterem hatte ich ja letztes Jahr den tollen Plan, immer wieder nachzukaufen. Das war sicherlich richtig. Aber was man kauft, war im wesentlichen bedeutungslos. 2021 war es nur wichtig, breit investiert zu sein. War ich. Ergo handelte es sich um massive (Vermögenspreis-)Inflation.
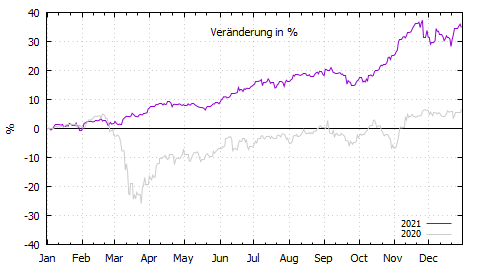
Die Erkenntnis, dass Stock-Picking zu viel Aufwand für zu wenig Ertrag ist, reifte bei mir schon länger. Deswegen habe ich es dieses Jahr weitestgehend aufgegeben. Im Gegenteil, ähnlich wie bei Softwarekomplexität, glaube ich nun auch für mein Depot: einfacher ist besser. Werte, die zu lange unter-performed haben (und von denen ich nicht mehr überzeugt bin), habe ich deswegen in den MSCI World umgeschichtet. Einzelwerte, die gut liefen (zum Beispiel MSFT, NVDA, PG), habe ich natürlich laufen lassen. Ich bin jetzt aber auch nicht aktiver Rebalancer. Mein Plan für 2022 ist, den relativen Anteil der Einzelwerte durch Aufblähen der ETFs (via Zuflüsse) zu reduzieren. An den nun insgesamt 12 Positionen in meinem Depot will ich festhalten.
Ein paar Worte noch zu Anleihen. Ich habe das jetzt in 8 Jahren 4 mal probiert und bin nur einmal mit ganz wenig Gewinn da rausgegangen. Ok, die Verluste waren auch ganz wenig, aber nach meiner Erfahrung sind Anleihen keine sichere Kiste, die in jedes Depot gehören. Wenn eh Verluste nicht ausgeschlossen werden können, kann ich auch gleich defensive Aktien (Nestlé) oder ETFs nehmen. Also irgendwas habe ich hier nicht verstanden. Und ich geb's auch auf - Anleihen fasse ich nicht mehr an.